

作者 | 朱勇椿、谢若冰、庄福振
编辑 | 陈大鑫
在推荐系统和广告平台上,内容定向推广模块需要尽可能将商品、内容或者广告传递到潜在的对内容感兴趣的用户面前。扩充候选集技术(Look-alike建模)需要基于一个受众种子集合识别出更多的相似潜在用户,从而进行更有针对性的内容投放。然而,look-alike建模通常面临两个挑战:
(1)一个系统每天可能需要处理成百上千个不同种类的内容定向推广实例(例如体育、政治、社会等不同领域的内容定向推广)。因此,我们很难构建一个泛化的方法,同时在所有内容领域中扩充高质量的受众候选集。
(2)一个内容定向推广任务的受众种子集合可能非常小,而一个基于有限种子用户的定制化模型往往会产生严重的过拟合。
怎么解决以上的挑战呢?
AI 科技评论今天为大家介绍一篇被KDD-2021收录的论文《Learning to Expand Audience via Meta Hybrid Experts and Critics for Recommendation and Advertising》,论文作者来自中科院计算所、腾讯微信看一看、北航。

论文链接:https://arxiv.org/abs/2105.14688
为了解决以上的挑战,这篇论文提出了一种新的两阶段框架Meta Hybrid Experts and Critics (MetaHeac)。
在离线阶段, 本文在不同种类的内容定向推广任务的历史行为数据上,采用元学习的方法训练一个泛化初始化模型。这个模型可以同时抓取不同任务之间的关系,从而能够快速适应新类别内容推广任务。
在线上阶段,针对一个新的内容推广实例,模型能够基于给定的种子集合和离线训练得到的泛化初始化模型,快速训练出这个实例的定制化推广模型。我们通过离线实验和线上实验验证了MetaHeac的有效性。目前,该框架已部署到微信中,用于部分内容定向推广场景。
1
背景介绍
在亿级别用户的互联网市场上,系统(内容分发算法、广告商)如何高效地将内容、广告或产品呈现到潜在的客户面前,成为了一个重要的任务。然而,内容定向推广中的内容往往拥有不同种类和不同受众,难以通过一个泛化模型进行处理。内容定向推广任务的一个关键技术就是扩充候选集技术(look-alike建模)。目前,也已经有很多公司部署了基于look-alike的内容定向推广系统,比如Google[1]、Linkedin[2]、Pinterest[3]、Ant Financial[4]、WeChat[5]等。
具体地,对于一个内容定向推广任务,系统会给定一个受众种子集合(包含一些对该次定向推广的内容感兴趣的用户)。基于look-alike的内容定向推广系统,旨在识别出更多的潜在用户,从而进行定向推荐。这些用户和种子用户非常相似,也极有可能是投放内容的潜在受众。高质量的扩充候选用户可以提升转化率,同时减少内容定向推广任务需要的费用。
基于look-alike的内容定向推广系统面临着以下两个挑战:
(1)不同的内容定向推广实例可能包含不同的内容,比如体育、政治、社会等。因此,一个公共的模型很难满足所有内容定向推广任务。
(2)一个特定的任务给定的种子集合可能只包含少量用户。基于这样的种子集合,一个定制化的方法很有可能会过拟合。特别是有的内容定向推广任务仅仅包含几百个种子用户,过拟合现象往往很严重。
传统的内容定向推广方法通常会使用一些制定的公共规则。经典的rule-based方法会通过一些人口统计数据来匹配相似的用户,这些方法通常效果不令人满意。传统的similarity-based方法使用一些人为定义好的相似度函数,比如cosine similarity等,来寻找相似用户。然而这类方法的效果极大取决于人为定义相似度函数的好坏以及特征的选取。最近几年,model-based方法针对每个内容定向推广任务训练一个定制化模型,取得了显著的效果提升。但是这些单阶段的model-based方法针对每个内容定向推广任务都需要从头训练模型,也容易产生过拟合。
针对传统模型的问题,一些model-based方法[3,4]将扩充候选集任务分为了两个阶段,offline和online。在offline阶段,这些方法训练一个公共的embedding层。在online阶段,它们基于这个embedding层训练一个定制化的模型。然而这些方法依然无法解决以下三个挑战:
(1)真实世界中的look-alike建模需要在新的内容定向推广任务上取得很好的表现,而公共的embedding层仅仅是在已有内容定向推广任务的数据上进行拟合,没有考虑泛化能力。
(2)已有模型直接训练公共的embedding层,没有考虑任务间的关系。事实上,不同任务之间可能有冲突,比如一个任务的种子用户可能对另一个任务推销的内容完全不感兴趣(负样本)。
(3)已有绝大多数工作仅仅预训练了embedding层,而没有考虑深度网络。因此,针对一个特定的内容定向推广任务,定制化的网络依然可能会过拟合。
为了解决这些问题,我们提出了一个新的两阶段扩充候选集框架Meta Hybrid Experts and Critics (MetaHeac)。
该框架也采用offline-online两阶段。核心是在offline阶段基于元学习训练一个泛化的模型。在online阶段基于前面的泛化模型训练一个定制化的模型。MetaHeac旨在训练一个更好的泛化模型,包含两个关键点:
(1)希望这个泛化的模型能够学到扩充候选集的能力。
(2)这个泛化模型应该学到在不同种类的内容定向推广任务中可迁移的知识。
2
系统概览
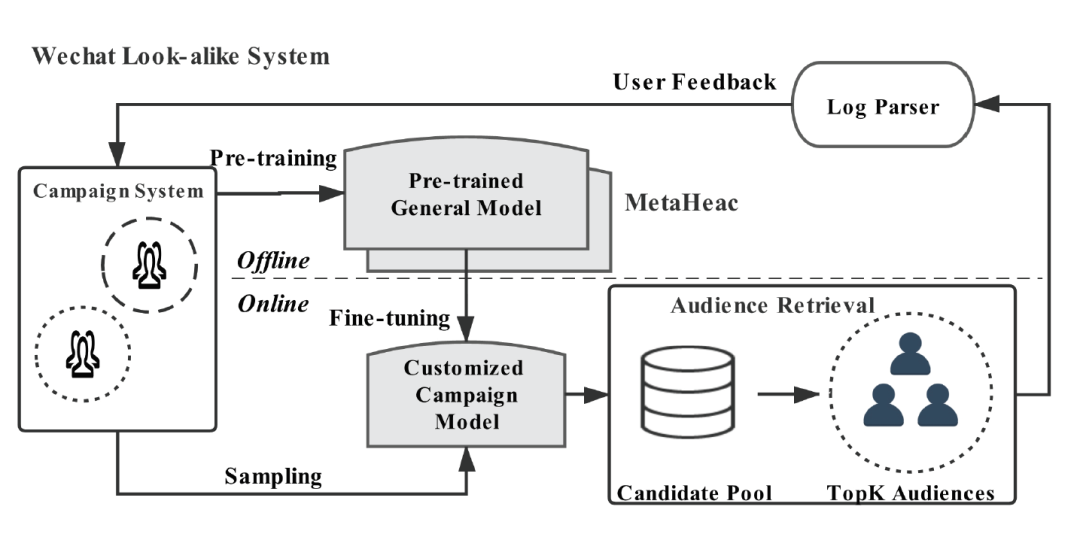
上图给出了一个简单的Look-alike系统示意图。一个内容定向推广任务系统存储着各种任务的数据,模型需要基于这些数据预训练得到一个泛化的模型,然后针对一个新来的内容定向推广任务,微调一个定制化的模型。得到这个定制化的模型后,模型从整个用户候选集中筛选出TopK个潜在的用户,向这些用户推广特定的内容。
3
模型方法
我们的模型是一个二分类的模型,输入为用户特征和内容定向推广任务的特征。一个定制化的模型可以表示为:
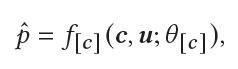
其中c表示特定的内容定向推广实例类别。
3.1 基于元学习的候选集扩充
我们回顾一下扩充候选集的流程:
(1)理解:这一阶段旨在理解种子集合中的用户特点,基于种子集合训练一个定制化的模型。
(2)寻找:这一阶段旨在基于定制化的模型,从候选集中找到潜在的客户。我们希望学习一个泛化的预训练模型,这个预训练模型能学会如何扩充候选种子集。因此,我们采用如下流程来模拟这两个阶段。
具体地,基于meta-learning中MAML的思想,我们把每个训练任务分为a和b两批样本,这两批样本来自同一个内容定向推广任务,但是样本不重叠,这两篇样本分别模拟理解和寻找两个阶段。在理解阶段采用如下损失函数:
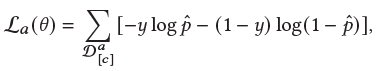
在寻找阶段,我们有了一个定制化的模型。为了泛化模型能够学会扩充候选集的能力,我们基于扩充的候选集训练损失,来更新泛化的模型:
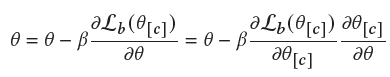
整个训练流程如下图所示:

3.2 混合专家和评论家系统
为了抓取任务间的关系,我们提出了一种混合专家和评论家系统。单个专家只擅长某几个特定领域,而多样的内容定向推广任务覆盖各个领域。综合不同的专家,能够覆盖不同领域的知识。因此,我们采用多个专家来提取用户的不同维度的表示。我们认为针对不同的内容定向推广任务,应该采纳不同专家提取的表示。基于这个假设,我们提出了一种任务驱动门,用以聚合所有专家给出的用户表示。具体公式如下:
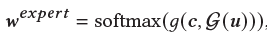
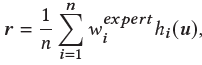
和专家不同,评论家旨在给出具体评分,判断用户是否对该次内容定向推广任务推销的物品感兴趣。我们也使用多个评论家,并且使用任务驱动门来聚合多个评论家的分数,具体公式如下:
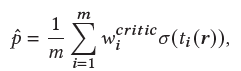
最后,整个混合专家和评论家系统可以表示为:
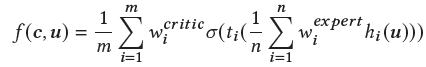
混合专家和评论家系统的框架图如下所示:
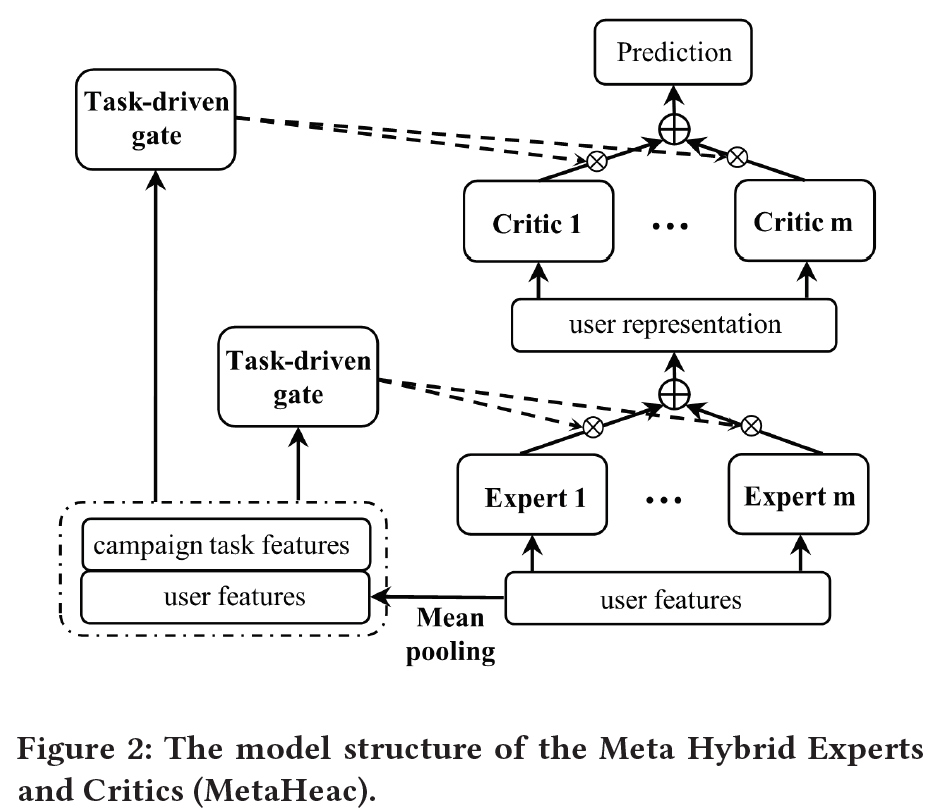
3.3 MetaHeac框架
整体MetaHeac的框架主要分为离线和线上两个阶段:
Offline:这个阶段我们使用元学习的方法来训练混合专家和评论家系统,这个模型作为泛化的模型。
Online:针对一个新来的内容定向推广任务,我们基于离线得到的泛化模型,使用该任务给定的种子用户,训练出一个定制化的模型,然后使用这个定制化的模型去扩充候选集。
4
实验
4.1 数据集
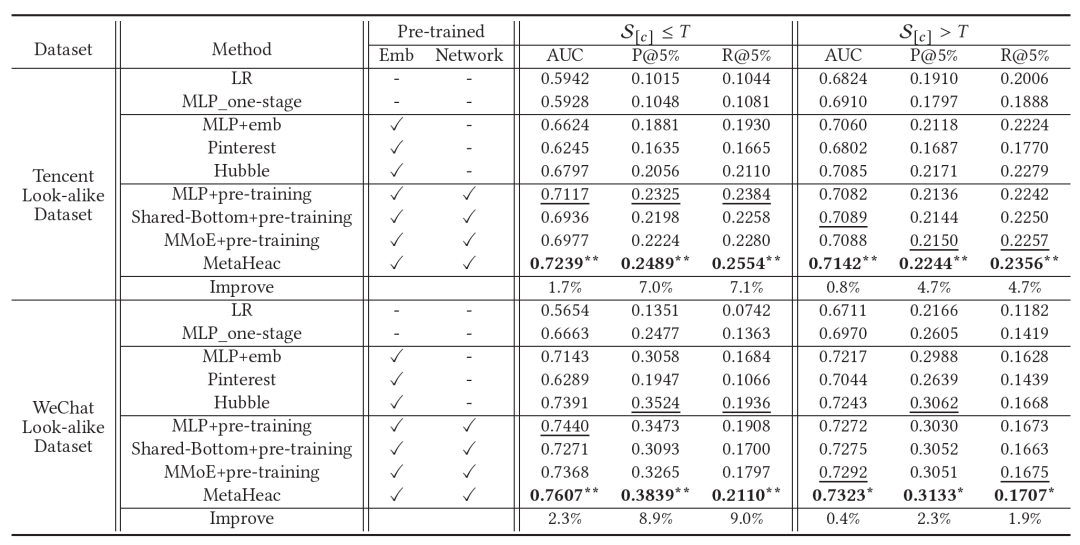
我们采用了腾讯广告大赛2018的Look-alike数据集以及WeChat内部的一个Look-alike数据。为了测试不同方法在不同规模的内容定向推广任务上的表现,我们根据内容定向推广任务给定的候选集大小进行划分,分为大于T和小于T两部分。腾讯广告数据T设置为4000,微信数据T为10000.
4.2 离线实验
我们根据baseline是否预训练embedding和network将所有方法划分为了三组,无预训练:LR、MLP_one-stage。只预训练Embedding:MLP+emb、Pinterest、Hubble。既训练embedding也预训练network:MLP+pre-training、Shared-Bottom+pre-training、MMoE+pre-training。实验结果如下图所示,可以看到在两种划分下我们的方法都取得了最好的效果。
4.3 线上实验
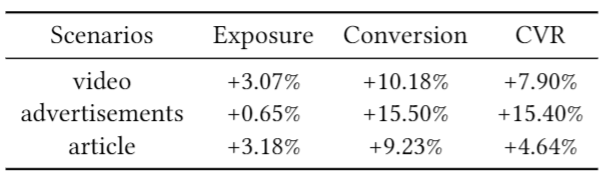
我们在大规模真实系统中的视频内容定向推广、广告推广、文章内容定向推广三个场景进行了实验,转化率都有显著提升,如下图所示。
4.4 消融实验
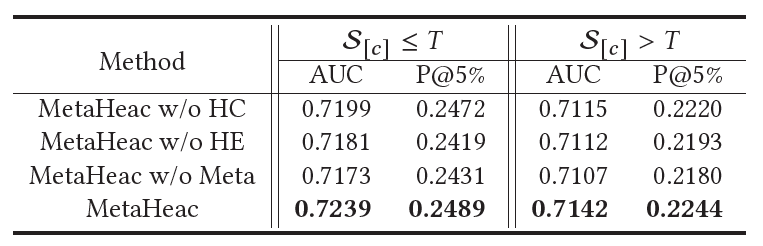
我们进行了消融实验,验证了我们提出的每一个模块都是有效的。
4.5 分析实验
我们通过t-SNE图分析不同内容定向推广任务的种子用户均值表示,以及评论家的任务驱动门的值。我们发现MetaHeac方法确实可以发掘不同内容定向推广任务之间的关系。相近的内容定向推广任务得到的种子用户表示以及门的权值也相近。
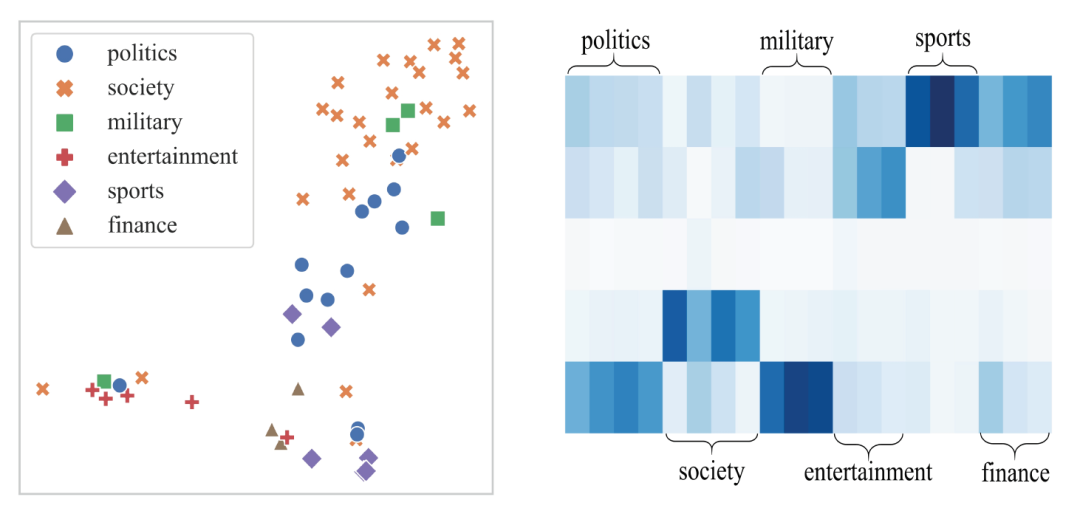
5
总结
为了解决推荐系统和广告平台中的内容定向推广问题,我们提出了一个新的框架MetaHeac。
在离线阶段,我们基于元学习的方法,训练得到了一个可以抓取任务间关系的泛化模型。在线上阶段,我们基于给定的种子集合微调泛化模型,可以很容易得到针对此种类内容推广任务的一个定制化的模型,用以寻找潜在候选用户。
线上实验和离线实验的显著提升验证了我们方法的有效性。目前,该框架已部署到微信中,用于部分内容定向推广场景。
参考文献
[1] Kanagal B, Ahmed A, Pandey S, et al. Focused matrix factorization for audience selection in display advertising[C]//2013 IEEE 29th International Conference on Data Engineering (ICDE). IEEE, 2013: 386-397.
[2] Liu H, Pardoe D, Liu K, et al. Audience expansion for online social network advertising[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2016: 165-174.
[3] deWet S, Ou J. Finding Users Who Act Alike: Transfer Learning for Expanding Advertiser Audiences[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 2251-2259.
[4] Zhuang C, Liu Z, Zhang Z, et al. Hubble: an Industrial System for Audience Expansion in Mobile Marketing[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 2455-2463.
[5] Liu Y, Ge K, Zhang X, et al. Real-time Attention Based Look-alike Model for Recommender System[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 2765-2773.
扫码加入KDD2021交流群:
若二维码过期或群内满200人时,添加小助手微信(AIyanxishe3),备注KDD2021拉你进群。




